What is Translation Memory and why is it important?
Translation Memory is a database that continually captures translations as translators work on translation projects.
Enterprise Translation Management Systems, such as TextUnited, can reuse existing translations, directly eliminating the need for translators to re-translate content. Additionally, they use Translation Memory as a foundation for improving machine translations. The whole process is completely automated and runs in the background.
Translation Memory vs. Terminology System
Translation Memory is not a terminology system, though. These two separate systems handle different data types and serve other purposes.
While the Translation Memory stores longer text strings, usually sentences, the terminology system focuses on collecting and managing terms and phrases. All the information captured in Translation Memory is based on the concept of a source sentence and a target sentence. When a new sentence comes in and the database finds a similar entry, it then shows the sentence to a translator as a proposal to use. If the sentence is labeled a ‘100% match’ in the Translation Memory, it is identified and marked as such. This immediate presentation as translated enables the translator to advance more quickly with the translation process.
Translation Memory offers a primary advantage in enhancing machine translation engine outcomes. Its main benefit, however, lies in facilitating faster, more cost-effective, and consistent translations.
The terminology management system provides the most significant benefit through the consistent use of specific multilingual terminology. This consistency is observed both by machine translation engines and translators.
Translation Memory is essential in an operational toolkit for any company dealing with multilingual content and communication with global audiences.
Historically, a Translation Memory was just a file handled by CAT (computer-assisted translation) desktop tools.
It was a very inefficient way of capturing, managing and reusing translations. It required much attention to collect files from translators, handle conflicting versions and provide the latest files for new projects. No surprise, the value of using these tools was limited.
Being a cloud-based, centralized system, TextUnited has eliminated all the inconveniences. It has also extended the speed at which the content from Translation Memory is leveraged across all projects at scale.
TMX format
A beneficial feature of Translation Memory is its TMX format, which readily exchanges its Translation Memory content between different translation systems. The secret of its success lies in its straightforward definition, so it is widely used in the translation industry.
As a result, moving from your desktop CAT tool to a company-wide TextUnited TMS system is a straightforward process. The only step is to import legacy TMX file(s) into TextUnited. Afterward, you can immediately start leveraging old translations in your TextUnited projects.
From that moment on, you can forget about ‘managing’ Translation Memory and rely on TextUnited to auto-pilot the whole process.
Once you create a new translation project, it automatically connects to the Translation Memory the content in the same language combination. The system will run an analysis of the project and match the new segments with existing segments in Translation Memory.
How does TM match the words?
Every time you upload a project, the system checks your translation memory for similar or identical sentences you’ve translated before. Depending on the degree of similarity, 100% identical segments will be put in place automatically (pre-translated). Anything below a 100% match will be available as a proposal that the translator can insert manually.
The degree of match is a percentage figure:
#1. 100% Match – If a segment in a translation memory matches the source segment exactly, it is called a 100% match. To qualify as such, the entire content of both the source document segment and the translation memory segment must match exactly. This includes all characters and character formatting.
#2. Context Match – Context Match is a 100% Match which, additionally, is accompanied by even more 100% Match segments. Such matches are usually repeated fragments of your old document in a new file being translated.
3#. Fuzzy Match – Everything below 100% is a fuzzy match.
Although the system cannot use Fuzzy Matches directly without the translator’s edits, they provide substantial savings. The human translation cost of fuzzy matches is calculated with a discount, applied for various levels of similarities! Expect a cost reduction of up to 40%.
Useful feature: Translation Memory Alignment
Translation memory alignment is another way to fill TextUnited Translation Memory with your legacy data from source and translated documents (files).
It is a life and money saver for everyone who likes effective solutions and does not have access to any TMX files. It allows you to import two language versions of the same file and convert them into translation units in the Translation Memory.
How to use it? To start aligning your translated material, you will need two separate language versions of a file. One is the source (original) language, and the other will be the translated version (target). The TM Alignment tool consists of four main options:
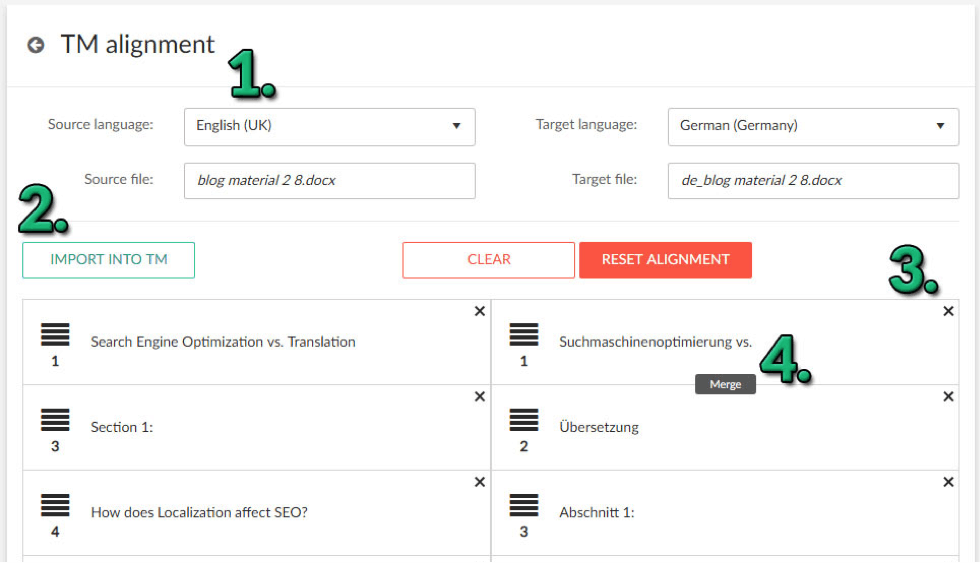
- Select source and target files (1) and the corresponding source and target language.
- Align source and target sentences by dragging segments by their headings. Next, delete unnecessary sentences (3) that cannot be aligned or merge them into one unit, if necessary (4).
- Import into TM (2). Once the alignment is done, use this option to import the translation units to a new or existing TM.
After clicking the Import into TM, the aligned segments are saved to the chosen Translation Memory and are ready for use in new projects.
Remember that using Translation Memory means that the more you translate through the system, the less work translators will have! Go ahead and achieve more for less. Sign-up for a free trial!
